Le numérique pense-t-il pour nous ?

Le numérique pense-t-il pour nous ?
Pierre Livet. Professeur émérite de l’Université d’Aix-Marseille, Centre Gilles Gaston Granger, UMR 7304
Résumé
Les outils numériques opèrent des recombinaisons de données, des corrélations statistiques et des relectures catégorielles, qui échappent à notre perception, mais peuvent nous « donner des idées ». Les internautes en font l’expérience lorsqu’ils interrogent un moteur de recherche ; les chercheurs recourent parfois à la simulation pour ajuster leurs hypothèses. Les machines qui individualisent les profils, grâce aux ontologies informatiques et au web sémantique, ne donnent pas toujours des résultats pertinents. Certaines de ces reconstructions peuvent cependant nous intéresser, sans que nous sachions d’emblée comment les relier à nos catégories usuelles. Le numérique multiplie les mondes et les sens possibles. La question est de savoir lesquels sont importants, cognitivement et collectivement. Si le numérique économise nos efforts, mais permet aussi de nous manipuler, quelles possibilités de découvertes et quelles nouvelles interactions humaines nous offre-t-il ?
Mots-clefs : intelligence artificielle, apprentissage automatique, réseaux neuronaux, algorithme, dynamiques de réseaux
Abstract
Digital tools operate data re-combinations, statistical correlations and categorical re-readings, which are beyond our perception, but can “give us ideas”. Internet users experiment this when they interrogate a search engine; researchers sometimes use simulation to adjust their hypothesis. Machines that individualize profiles, thanks to computer ontologies and the semantic web, do not always give relevant results. But some of these reconstructions may interest us. The question is to know which one are important, cognitively and collectively? If the digitals systems save our efforts, but also allows to manipulate us, what possibilities of discoveries and what new human interactions do they offer?
Keywords: web ontology, resource, naming, internet, artificial intelligence
I. Pensée, concepts, et contextes
Pour essayer de répondre à la question « est ce que le numérique pense pour nous ? » un philosophe est tenté de commencer par poser une autre question : « Qu’est-ce que penser ? ». Si on suit Kant, c’est utiliser des concepts. Qu’est-ce qu’un concept ? Un concept est supposé rassembler sous une unité une diversité de données.
 Les philosophes ont eu tendance à organiser les concepts en « arbres », avec un concept général (celui d’entité, par exemple) à la racine de l’arbre et des concept plus spécifiques (propriétés, individu, etc. ) qui commencent des ramifications, allant toujours vers des concepts encore plus spécifiques. C’est ce que je nommerai l’approche de catégorisation. Mais c’est là une mise en ordre des concepts, qui intervient après coup, ce qui suppose qu’on ait déjà utilisé les concepts. Elle ne correspond donc pas au fonctionnement principal des concepts. On n’envisage pas un concept tout seul, ni forcément selon cette structure d’arbre. Un concept permet de faire des inférences valides dans le contexte d’usage du concept. Par exemple le concept de « triangle » est utilisé en général pour désigner une forme spatiale, et permet d’inférer qu’on va trouver trois sommets, trois côtés, qu’il s’agit d’une figure close, etc. Ces inférences ne restent pas forcément confinées au contexte d’usage initial (le contexte géométrique), car des inférences moins réglées que les inférences logiques, des inférences analogiques vont pouvoir mener à un autre contexte d’usage, quand on parle par exemple d’alliance ou de coalition triangulaire. Et ce qu’on appelle couramment « penser », que cela consiste simplement à avoir une opinion (« je pense que le numérique empêche de penser ») ou à pouvoir la défendre ou la discuter, consiste à utiliser les concepts non seulement selon leur mode d’inférence pertinent dans un contexte, mais aussi par analogie pour passer d’un contexte à un autre.
Les philosophes ont eu tendance à organiser les concepts en « arbres », avec un concept général (celui d’entité, par exemple) à la racine de l’arbre et des concept plus spécifiques (propriétés, individu, etc. ) qui commencent des ramifications, allant toujours vers des concepts encore plus spécifiques. C’est ce que je nommerai l’approche de catégorisation. Mais c’est là une mise en ordre des concepts, qui intervient après coup, ce qui suppose qu’on ait déjà utilisé les concepts. Elle ne correspond donc pas au fonctionnement principal des concepts. On n’envisage pas un concept tout seul, ni forcément selon cette structure d’arbre. Un concept permet de faire des inférences valides dans le contexte d’usage du concept. Par exemple le concept de « triangle » est utilisé en général pour désigner une forme spatiale, et permet d’inférer qu’on va trouver trois sommets, trois côtés, qu’il s’agit d’une figure close, etc. Ces inférences ne restent pas forcément confinées au contexte d’usage initial (le contexte géométrique), car des inférences moins réglées que les inférences logiques, des inférences analogiques vont pouvoir mener à un autre contexte d’usage, quand on parle par exemple d’alliance ou de coalition triangulaire. Et ce qu’on appelle couramment « penser », que cela consiste simplement à avoir une opinion (« je pense que le numérique empêche de penser ») ou à pouvoir la défendre ou la discuter, consiste à utiliser les concepts non seulement selon leur mode d’inférence pertinent dans un contexte, mais aussi par analogie pour passer d’un contexte à un autre.
Les concepts sont signalés par des mots, et par les insertions d’un même mot dans des phrases et des textes qui peuvent être semblables mais aussi différents. Ils sont aussi signalés par des schémas, voire évoqués par des images et par les relations entre les éléments des schémas et des images. Nous pouvons avoir des pensées que nous n’arrivons pas à exprimer dans des symboles ou des images stables qu’une autre personne pourrait imaginer sans en changer les propriétés caractéristiques, mais nous les nommerons alors plutôt des intuitions que des concepts.
Quand je pars d’un mot (ou groupe de mots) et que je veux trouver son sens, c’est que je tiens le mot pour lié à un concept. Je pourrais vouloir chercher sa définition. Mais le dictionnaire me donnera alors une phrase qui « définit » le mot en le remplaçant par d’autres mots. Or ce remplacement ne sera valide que dans un certain contexte (pensez à « étoile », corps céleste ou vedette de ballet ou de cinéma, ou à « rencontre », entre deux amis ou bien deux aérolites qui s’entrechoquent). Qu’est-ce que je peux faire pour avoir une idée du contexte ? Je vais chercher des phrases dans lesquelles un même mot joue un rôle, et d’autres dans lesquelles il en joue un autre, ce qui distinguera les contextes, sans oublier les phrases dans lesquelles il est simplement incongru. Le repérage du même mot dans différentes phrases va donc permettre de dessiner des chemins qui relient ces phrases, et ces différentes phrases relient ce même mot à des mots différents. Au lieu de chercher une définition, toujours discutable, je pourrai donc me borner à relier entre elles toutes les phrases qui contiennent ce mot.
Cependant il faut pouvoir différencier les contextes d’usage. Pour cela on va tenter de repérer des groupes de phrases qui correspondent à tel ou tel usage. Entre des groupes de phrases qui appartiennent à des contextes différents, il va y avoir moins de mots communs qu’au sein du groupe relié au même contexte. On pourra donc avoir des liens renforcés entre les phrases qui ont beaucoup de mots en commun, et des liens plus faibles entre phrases qui ont moins de mots en commun.
Tout cela nous amène à imaginer les liens entre mots, ces liens qui sont des images (partielles) des usages des concepts, comme similaires aux liens d’un réseau, avec des sous-réseaux qui sont les différents contextes d’usage. Les liens à l’intérieur d’un sous-réseau, d‘un contexte d’usage, sont plus fréquents et plus probables. On peut leur donner un poids plus important qu’aux liens entre différents sous-réseaux, liens qui seront moins fréquents. De même il peut aussi y avoir des liens entre certains sous-réseaux qui sont plus fréquents que d’autres liens entre d’autres sous-réseaux, et qui ont donc aussi plus d’importance. Ces liens, et leurs importances, ne sont pas immuables, ils évoluent en fait plus ou moins vite avec les usages.
Cette approche, qu’on pourrait appeler l’approche de dynamique des réseaux, nous l’utilisons pour penser, mais sans pouvoir en calculer tous les liens. Le calcul de tous ces liens est rendu possible par une approche numérique. Elle est différente de l’approche de catégorisation, en particulier parce qu’elle peut être évolutive : le sens d’un concept peut évoluer en fonction des transformations du réseau d’inférences. Certains liens qui reliaient des sous-réseaux sont abandonnés, d’autres créés, et cela sans cesse.
2. Centralité sociale et « pages » Google
On retrouve ces principes dans les outils numériques, et par exemple dans le ou les algorithmes utilisés par Google. Je rappelle que les principes sont les suivants : construire des réseaux de liens entre mots, possiblement entre concepts, pondérer ces liens en fonction de leur fréquence ou de leur importance, de manière à voir apparaître des différences de structure, de formes dessinées par les liens dans des réseaux, et tenir compte en permanence de l’évolution de cette structure.
L’approche numérique est ici partie d’un algorithme proposé par Katz, puis Bonacich (années 70) et développé plus de vingt ans plus tard par Brin et Page (Google) en trouvant à l’essai le choix de paramètres qui rendent le calcul praticable. Or, cet algorithme était utilisé initialement non pas pour traiter des mots et des concepts, mais pour évaluer dans un réseau social (d’interactions entre des personnes ou entre des entreprises) l’importance ou centralité d’un acteur.
L’idée la plus simple de cette notion de centralité peut être donnée par une forme particulière de réseau : si vous êtes au centre d’un réseau en étoile, vous êtes plus important pour le réseau que les autres nœuds du réseau.
Mais cette image simple ne rend pas bien compte d’autres structures, en particulier d’une structure pyramidale, où le PDG, patron, ou chef, est supposé le plus important. On peut cependant supposer que le « chef » est relié à plusieurs membres du réseau très influents directement, que ceux-ci sont reliés à d’autres membres, etc. si bien que le chef est relié indirectement à tous. On pourrait imaginer que tous pourraient avoir à faire passer leurs informations par le chef si bien qu’on aurait alors une forme en étoile, mais cela serait un peu vain, parce que le chef aurait du mal à pondérer toutes ces informations. On peut donc avoir des chemins très longs qui partent de notre « chef » pour aller jusqu’à une unité de base, des ramifications très développées de chemins qui partent du chef vers une foule d’unités de base, et enfin des variantes par rapport à ces chemins qui vont vers les nœuds subordonnés en faisant des détours. Les détours sont aussi intéressants, car ne s’agit pas d’un arbre, mais d’un réseau : on peut commencer par visiter un voisin du nœud visé au lieu d’aller directement vers ce nœud ; tous les chemins comptent, pas simplement les plus courts. On retrouve ces trois dimensions (longueur du chemin, nombre de nœuds atteints, variété des chemins et détours possibles) dans des réseaux qui n’ont pas de structure pyramidale, qui sont en ce sens « décentralisés ». Ces dimensions donnent dans les deux cas des indices de « centralité » d’un nœud dans un réseau.
Bonacich a utilisé les mathématiques du calcul matriciel, et en particulier la notion de valeur propre pour pouvoir calculer étape par étape ce degré de centralité. Katz a aussi proposé de diminuer l’importance des liens très éloignés (les satellites lointains). Les lanceurs de Google ont ensuite ajusté les paramètres. Ils ont enfin utilisé les calculs sur la centralité pour ordonner dans un ordre approprié les références (les « pages ») auxquelles Google peut renvoyer l’internaute. Il s’agit de présenter d’abord, en fonction d’une requête, les pages ou références qui sont les plus « centrales » pour cette requête requête, donc les plus immédiatement accessibles à partir des termes de cette requête, tout en ordonnant les pages selon ces degrés de centralité.
C’est là utiliser une analogie entre la centralité, l’accessibilité et la pertinence d’une page pour une requête. Mais si nous revenons sur l’analogie faite entre la centralité et l’importance sociale, nous voyons que cette analogie peut poser problème (comme toute analogie).
La « centralité sociale » peut être d’abord comprise en deux sens très différents : vous êtes « central » parce que beaucoup d’informations doivent ou se trouvent passer par vous (secrétaire) ; vous êtes central parce que vos décisions influent sur les conditions de travail de beaucoup de gens (PDG). Un exemple qui réunissait les deux est celui du ministre de la police Fouché (influent de la Révolution, et l’Empire, jusque pendant la Restauration), par qui toutes les informations passaient, et qui pouvait décider du sort de tous les suspects !
Mais il y a un troisième sens : vous êtes central en ce que les chemins qui passent par vous permettent de mieux identifier une sous-partie, un sous-ensemble d’interactions, de liens au sein du réseau de toutes les interactions.
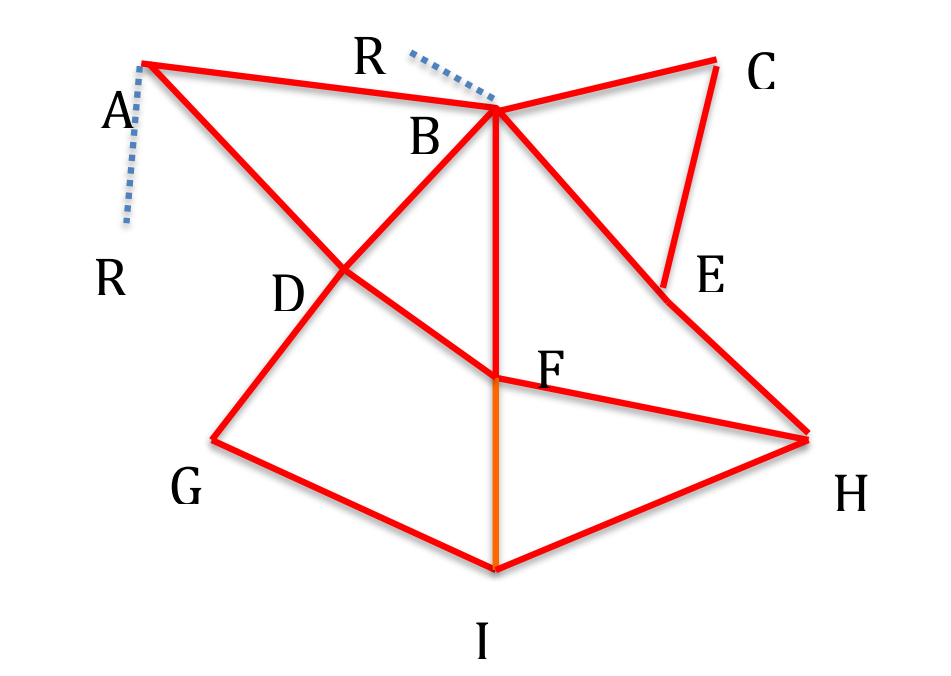
B : via 1 étape, =>5 nœuds; 2 étapes, =>10; 3 étapes =>10, etc.
F : =>4, =>9; =>10, etc. 3 étapes sont nécessaires pour arriver de n’importe quel nœud à n’importe quel nœud. Une mesure de centralité qui considère les chemins partant du nœud considéré et présentant ces différents nombres d’étapes donnera l’avantage à B.
Dans le schéma que j’ai fait, je n’ai représenté qu’un sous-réseau, un groupe. De manière interne au groupe, B et F sont les plus centraux (B est un peu plus central que F). Mais j’aurais dû développer les autres sous-réseaux qui sont accessibles par les liens en pointillés. Au lieu de zoomer comme je l’ai fait sur ce sous-réseau, zoomons en imagination sur l’ensemble des sous-réseaux auxquels il serait relié. La centralité de A, par exemple, n’est pas aussi élevée que celle de B si nous nous bornons au sous-réseau initial. Mais si A est relié à un autre sous-réseau important R2, alors que B est relié à un sous-réseau R3 moindre, la centralité de A sera bien supérieure. Et ainsi de suite : si R2 est relié à peu d’autres sous-réseaux, et R3 à beaucoup d’autres, la centralité de B redeviendra plus importante que celle de A.
Or ces variations de la centralité sont liées à ce que dans certaines zones, les liens sont denses, alors que d’autres, ils le sont moins. Les nœuds ou individus qui sont reliés à tout le monde dans une zone dense sont importants pour le groupe du sous-réseau, de manière interne, alors que ceux qui sont dans une zone peu dense, mais qui relient des sous-réseaux entre eux, sont importants pour les relations intergroupes.
Supposons que notre sous-réseau soit le groupe formé par les membres d’une association. Prenons deux personnages de l’association : son président, et l’homme à tout faire que tous connaissent dans l’association. Ici les deux « niveaux sociaux » d’homme à tout faire et de président permettent de déterminer et les membres de l’association (de manière interne) et l’association par rapport aux autres associations (relation inter-associations). En effet l’homme à tout faire a des liens internes au groupe avec chacun de ses membres, et le président, lui, est souvent relié à d’autres réseaux, d’autres groupes, c’est un « hub » (pour employer une autre analogie, avec les aéroports qui sont des relais pour aller dans différentes directions). Or c’est la conjonction des deux types de rôles (purement interne, ou bien reliant l’intérieur et l’extérieur) qui permet de déterminer l’association au sein d’autres structures.
On peut donc utiliser cette analyse du réseau à la fois pour mieux savoir qui est relié à qui ou qu’est-ce qui est relié à quoi, pour savoir qui influence qui ou qu’est-ce qui influence quoi, et pour savoir distinguer des liens préférentiels qui définissent un sous-groupe au sein d’un réseau (on a plus de chances d’avoir des liens avec des membres de son groupe qu’avec des membres d’autres groupes).
Nous pouvons maintenant revenir à notre problème de la pensée et des concepts. Si nous avons une conception relationnelle et inférentielle des significations, et de l’usage des concepts, donc de la pensée en fonctionnement, un tel dispositif semble tout désigné pour rendre cette conception opératoire, et pour la relier à des calculs sur les réseaux.
En effet, une fois que, pour un corpus de mots donné, on a réalisé ce programme de structuration en sous-réseaux, on peut tenter d’identifier des types de parcours entre sous-réseaux. Si vous restez dans votre sous-réseau, par exemple si vous consultez des ouvrages d’économie, Google vous aiguillera sur d’autres ouvrages d’économie, et de même, si vous consultez des ouvrages de neurosciences, il vous proposera des ouvrages de neurosciences. Mais la chose intéressante est que si plusieurs chercheurs consultent des ouvrages d’économie et de neurosciences, on pourra constituer un sous-groupe transversal (le groupe des neuroéconomistes) et proposer à ces chercheurs des références qui combinent les deux types de discipline (en partant de leurs titres, de leurs mots clés, voire en tenant compte de tous les mots reliés au vocabulaire des neurosciences et au vocabulaire de l’économie au sein de tout le texte)[1].
On peut ainsi construire un profil pour chaque internaute, qui est celui des groupes qu’il visite. Il ne visite pas tout le réseau, mais seulement des sous-réseaux ou groupes. Et cela permet de pondérer les liens ou connexions, et de donner plus d’importance aux connexions qui sont fréquemment empruntées.
Cela permet finalement au chercheur de trouver plus vite les textes qui correspondent… à son profil tel que ses recherches précédentes ont pu l’esquisser. Bien sûr, cela ne satisfera le chercheur que s’il trouve aussi dans les textes proposés de nouveaux concepts, alors que le dispositif Google l’aiguille sur les textes comprenant surtout des concepts qu’il connaît déjà.
3. Variations et innovations ?
Le dispositif de type Google nous donne donc accès à des textes similaires à ceux que nous avions déjà consultés. Cependant, ce dispositif n’est pas strictement conservateur. Mais ses capacités innovantes ne tiennent pas à Google. Heureusement, il y a suffisamment de différences entre les internautes, et leurs comportements de recherche présentent des variations. Or des variations simplement aléatoires de comportements dans une grande masse peuvent introduire du nouveau, ce qui fait que les « groupes » ne resteront pas totalement stables. Certes, cette instabilité liée aux variations et ce renforcement lié aux contagions entre internautes peuvent se renforcer l’un l’autre, et ont des chances de produire des effets d’emballement sur des modes. On peut malgré cela voir dans la recombinaison des contextes une source d’innovation, voire « la » source d’innovation fondamentale.
Mais si c’est là un des facteurs nécessaires d’innovation, ce n’est pas un facteur suffisant. En effet la grande majorité des recombinaisons entre mots (ou concepts) ne sont pas productives au sens où elles ne permettent pas de généralisation et systématisation. Par généralisation et systématisation, j’entends la production méthodique de nouvelles combinaisons pertinentes qui permettent de réinterpréter les précédentes combinaisons conceptuelles selon des perspectives jusque-là insoupçonnées.
Pourtant il est clair que la capacité du numérique à gérer un très grand nombre de combinaisons et à faire varier ces combinaisons, fût-ce de manière simplement aléatoire, va permettre d’envisager une multiplicité de possibles. Leibniz, déjà, avait bien vu qu’en tentant toutes les combinaisons et en éliminant les possibles contradictoires entre eux, on peut engendrer une multiplicité de mondes possibles. Mais il supposait que Dieu avait fait, entre ces mondes possibles le choix du meilleur. Nous ne disposons cependant pas d’un Dieu leibnizien pour faire le choix du meilleur (ou du moins pire) de ces mondes possibles. Mais, à condition d’abandonner l’idée qu’il n’existe qu’un seul meilleur monde, nous pouvons penser remplacer ce Dieu par la compétition entre les possibles. Ce ne serait que reprendre et développer de manière plus rapide ce qu’est censé être un processus évolutionnaire : une concurrence entre les espèces où celles qui gagnent sont celles qui arrivent à se reproduire de manière plus stable que les autres.
Les algorithmes de « deep learning » sont d’ailleurs basés sur ces deux principes de combinaison et de compétition : on tente diverses combinaisons qui définissent les poids des liens sur un réseau à plusieurs couches, on fait fonctionner la dynamique du réseau, on fait entrer en compétition plusieurs réseaux de ce genre, ou plusieurs versions des répartitions des poids, on sélectionne ainsi un réseau, et on recommence plusieurs fois ce double processus de combinaison et de compétition.
On peut arriver ainsi à des programmes qui battent les meilleurs joueurs d’échec et de go. Mais il s’agit là d’un contexte très limité, contraint par des règles strictes. Est-ce que ce genre de démarche pourrait nous assurer un fonctionnement évolutif qui s’adapterait de lui-même à tous les contextes d’usage ? On obtient de bonnes performances pour les détections de formes dans des images – par exemple des images de scanner – et de phonèmes dans des vocalisations. Ces formes et ces phonèmes peuvent être rattachées à des catégories et des mots, donc à des symboles conceptuels. Cela ne peut pas être garanti pour toute donnée à analyser. Changer quelques pixels sur une image peut conduire à des erreurs. La démarche d’apprentissage en question est sensible aux évaluations qui ont guidé la sélection à des étapes intermédiaires. Or la bonne évaluation serait évidemment celle qui, à chaque étape, resterait aussi pertinente pour évaluer les performances finales – mais précisément, on ne dispose pas de ces performances finales à des étapes intermédiaires. Il y a là une limite fondamentale. Prenons un processus émergent innovant. S’il est innovant, c’est qu’il n’est pas similaire à des processus émergents dont on aurait déjà pu évaluer les propriétés, par une analyse qui serait forcément rétrospective. Or on ne peut analyser rétrospectivement ses propriétés tant qu’il n’a pas émergé. On ne peut donc définir d’avance ou même en cours de route les bons guides ou filtres qui nous diraient quel est le meilleur processus d’émergence de ce processus émergent innovant.
Cependant, si on ne se soucie pas d’optimalité, mais seulement d’efficacité limitée et à court terme (en particulier d’efficacité marchande), les outils numériques sont très aisés à utiliser pour manipuler les consommateurs du numérique, par exemple en orientant les liens entre internautes de manière préférentielle vers différents sites (commerciaux) ou au contraire en rendant difficile l’accès vers d’autres sites (qui font des évaluations plus critiques).
4. Conclusion partielle
Nous sommes arrivés à une réponse partielle à notre question, « le numérique pense-t-il pour nous » ? Le numérique permet (entre bien d’autres utilisations) une approche des concepts par les dynamiques de réseaux, et cette approche correspond à certains aspects de l’usage des concepts, et donc de la pensée. La réponse est donc positive en ce sens que le numérique (ou plus exactement notre utilisation du numérique) permet bien une activité qui a des similitudes avec la « pensée ». Cette réponse porte sur la première partie de la question : « le numérique pense-t-il ? », et elle lui donne le sens suivant : « le numérique pense avec nous ». Le numérique ne pense pas tout seul ; mais nous non plus, rappelons-le : non seulement nous pensons avec d’autres, mais nous pensons avec des symboles et des images.
On peut donc ajouter que le numérique rend manifeste que « penser » n’est pas une activité solitaire et égocentrée, mais au contraire est une activité en réseau. Il montre même davantage. Il montre aussi que les interactions qui nourrissent ces réseaux ne sont pas seulement les interactions qu’un penseur a directement avec d’autres penseurs. Le réseau va bien au-delà de ces interactions directes – que chaque partenaire peut penser contrôler. La pensée se révèle ici collective. On l’a vu, cela implique des possibilités d’innovation, mais cela a aussi pour conséquence que les évolutions de ces tentatives d’innovation ne sont pas individuellement maîtrisables.
Le problème que nous avons encore tient à la deuxième partie de la question : si le numérique permet une activité de type « pensée », pense-t-il « pour nous » ? ce « pour nous » peut avoir un double sens : « en notre faveur », mais aussi, « à notre place ».
5. « A notre place » ? « En nous relayant » ?
La réponse « à notre place » mène à une vision complotiste du numérique, qui y verrait simplement un instrument de manipulation des foules via la manipulation de l’accès aux symboles et aux images. On a d’ailleurs montré que le net est aussi un dispositif qui permet des renforcements des liens entre tenants de théorie du complot (Del Vicario et al. 2016). Sur le net, les complotistes vont se rapidement se regrouper et renforcer les uns les autres leurs opinions complotistes (un problème est que les internautes qui voient très facilement des complots dans notre monde sont aussi ceux qui sont les plus crédules par rapport à des informations fausses mais qui présentent des théories alternatives à celles qui sont les plus couramment admises et validées par des autorités scientifiques). Cette version complotiste peut avoir un certain succès auprès des dictatures, qui arrivent souvent au pouvoir en prétendant dénoncer un complot, puis qui s’y maintiennent en justifiant leurs mesures policières par l’existence de complots. Mais elle n’est pas beaucoup plus réaliste que la vision idyllique du numérique. Dans cette version idyllique sympathique,j la réponse à la question « pour nous » serait plutôt « en nous relayant ». Ceux qui partagent cette vision pensent que le numérique assure l’accès de tous à toutes les informations, la fin des monopoles et la possibilité d’une véritable démocratie.
Le dictateur risque d’être surpris par les dynamiques du numérique. Car s’il est bien vrai que le numérique développe des dynamiques de réseau, alors il développe aussi des effets émergents, avec les possibilités de variation et d’emballement que nous avons mentionnées. Le manipulateur tyrannique verra son mode de gouvernance produire des effets qu’il n’avait pas prévu. Les internautes qui voient dans le Web la grande démocratie peuvent eux aussi être déçus. Il n’est pas garanti que les effets émergents collectifs des dispositifs supposés relayer les ambitions démocratiques respecteront leurs souhaits : on vient de voir que le Web entretenait et favorisait les théories complotistes. Pourtant des processus d’émergence assez voisins, mais à une échelle plus limitée, et entre des esprits avertis et ouverts, produisent des effets de coopération et d’innovation- et au pire, amènent les groupes à se reformer sans cesse de manière différente.
En quel sens alors entendre le « pour nous » ?
Le numérique accroît notre capacité d’investigation et d’échanges. Cela nous donne une raison de soutenir que ce « pour nous » veut dire « en notre faveur » (à tout le moins en faveur de ceux qui disposent de cette capacité étendue, relativement à ceux qui en sont privés). Cette « faveur » ou avantage a, rappelons-le, un double aspect : d’une part, le numérique permet de faire émerger des différences entre les sous-réseaux qui finissent par se distinguer, d’autre part, inversement, il permet de suggérer de nouvelles connexions d’un sous-réseau à l’autre. Dans le domaine de la recherche académique, par exemple, le premier aspect permet de distinguer des disciplines. Les graphes qui montrent l’évolution des concepts de quelques disciplines permettent de montrer l’évolution de leurs frontières respectives. Mais inversement l’étude des réseaux de concepts permet de suggérer des connexions interdisciplinaires, voire transdisciplinaires. Ce genre d’analyse numérique des réseaux permet de rendre visible un système de concepts et de le distinguer d’autres systèmes de concepts, mais comme ces divisions restent relatives, il permet aussi de mieux identifier des ponts possibles entre systèmes conceptuels, ou encore de mieux percevoir l’évolution des usages des concepts et de leurs liens (cf. les travaux de Chavalarias, Cointet, et Roth).
6. Usages évaluatifs
Il est cependant un usage des concepts que ce système d’opérations sur des réseaux a des difficultés à proposer, c’est leur usage évaluatif, sinon normatif. Quand nous utilisons les concepts pour nos inférences, ce que nous entendons par « maîtriser un concept » – l’utiliser pour nos objectifs, c’est guider une inférence, en partant de ce concept pour aller vers certains concepts plutôt que vers d’autres. Cet usage des concepts, comme le « plutôt » qui indique une préférence le montre, est donc au moins implicitement évaluatif. La dynamique des réseaux, elle aussi, peut avoir des effets évaluatifs. En effet elle peut renforcer des liens plutôt que d’autres. Mais là encore, ces effets peuvent nous amener à seulement nous focaliser sur des évaluations partagées par notre propre groupe – le groupe qui émerge de la convergence des interactions.
Cependant, nous pouvons aussi être attentifs aux évolutions sur le réseau, et quand nous voyons des évaluations qui ont tendance à exclure d’autres interactions de type différent, à disqualifier des interactions qui divergent quelque peu de celle de notre groupe, nous pouvons prendre le contrepied de cette tendance. Nous pouvons adopter une perspective trans-groupes.
Il faut rappeler ici que quelques premières tentatives d’utiliser le deep-learning, déjà cité, pour produire un logiciel qui développe une conversation de type humain, ont amené un logiciel conçu par Microsoft à tenir des propos racistes. La raison en est sans doute que les propos racistes sont plus facilement identifiables en tant que propos de groupe : ils ressassent ad nauseam un petit nombre de concepts clichés. L’usage de ces concepts simplificateurs voire caricaturaux se distingue assez clairement des autres usages des concepts – par exemple on y est peu sensible à la réfutation par un argument contraire, on y refuse de s’engager dans des distinctions, de développer une longue chaîne d’arguments pesant le pour le contre, etc.
Dans le cas des propos racistes, a été privilégiée la tendance à la convergence sur les mots du groupe, qui n’a pas été pondérée par la tendance trans-groupes. Cette tendance à se focaliser sur des convergences a comme effet rebond de dramatiser les divergences. Elle privilégie ainsi le mode évaluatif qui oppose l’in-group et l’out-group. Elle ne veut pas entendre parler du mode évaluatif de la perspective trans-groupes, qui impose de mettre en discussion nos évaluations et celles des autres.
7. Pensée de groupe et perspective trans-groupes
Or, comme le montre l’histoire des idées et l’histoire de la philosophie, c’est pourtant cette perspective trans-groupes qui a permis de constituer le concept de « sujet pensant ». Le sujet pensant est ce sujet individuel à qui il reste possible de se distinguer de ses groupes d’appartenance, en particulier de sa cité, de son pays d’origine et de ses coutumes. C’est ce sujet, ce « je », qui semblerait devoir être, une fois mis au pluriel, le véritable « nous » de notre question.
En philosophes, nous pourrions croire que cette perspective du sujet qui ne se réduit pas à ses groupes d’appartenance est la seule que nous devrions privilégier. Mais la mise en œuvre numérique et collective du « penser », avec sa double face (effets de masse et innovations), nous rappelle que les processus de réseau suscitent les modes mondiales et globalisantes – bien qu’instables – ou encore le racisme de groupe et les effets de renfermement communautaire. Et cela, alors même que ce sont aussi les processus de réseau qui permettent les usages trans-contextuels des concepts et le développement de perspectives trans-groupes. Et ces deux effets de phénomènes collectifs échappent tous les deux à la maîtrise des sujets individuels. Ces deux effets principaux d’une mise au pluriel des pensées échappent même au contrôle que des associations volontaristes souhaiteraient exercer pour privilégier les relations « trans-groupes ».
« Nous », individus pris en tant que membres de collectifs, sommes des « nous » du numérique. La dualité des effets collectifs du numérique ne doit pas pour autant nous amener à renoncer à utiliser les outils par lesquels le numérique fait penser. Il nous permet de lancer des modes innovantes, d’affirmer des identités interactives, de constituer des associations, de transgresser les frontières des communautés et des disciplines. Mais « nous » devons être conscients de ce que les dynamiques que ces outils activent peuvent conduire à des émergences collectives qui n’auront pas que ces aspects souhaités. Nous devons prévoir cela. Nous devons être conscients de la dualité de ces tendances. Et c’est pour cela que « nous » devons lutter contre l’analphabétisme et le pur consumérisme numérique. Nous deviendrons alors plus experts et plus vigilants dans nos usages du numérique, et nous travaillerons à mieux connaître les mécanismes de ses doubles effets (en recourant par exemple à des simulations de ces effets, en utilisant donc le numérique pour anticiper ses effets nocifs). Cela consiste à utiliser le numérique pour des simulations de ses effets nocifs aussi bien que de ses effets bénéfiques. C’est seulement à cette condition que le numérique ne pensera pas à notre place.
8. Conclusion
Or, se livrer à ce genre de réflexions qui s’appuie sur des simulations pourrait nous amener à réviser la formule : « penser c’est créer des concepts », que l’on attribue à Deleuze. Nous ne pouvons plus supposer implicitement que cette création soit une activité qui se réduise à l’expression d’une puissance native et directement productrice. En fait nous essayons des usages de termes, ce qui est au fond une forme de simulation des effets de ces usages, et quand nous arrivons à les utiliser de manière réitérable dans un réseau d’inférences qui est suffisamment étoffé, nous pouvons penser que nous avons sinon créé, du moins mis à l’épreuve des concepts. Mais les algorithmes ne sont pas loin de jouer un rôle assez similaire : tester la puissance inférentielle d’un terme selon ses liaisons supposées avec tout un ensemble de termes. Un programme révèle sa vitesse de calcul, et on peut imaginer des variations de programmes qui révèleraient des moyens d’accélérer le calcul.
Cela, comme le dit Mathias, se passe pour l’essentiel « hors de notre conscience ». Or la maturation et le frayage de voies d’inférence plus rapides dans notre propre cognition sont aussi en dehors de notre conscience – ce sont seulement les résultats de ces processus dont nous pouvons prendre conscience, comme nous pouvons prendre conscience, par comparaisons, de certaines différences entre programmes. « Ça pense » en nous, comme le disait Nietzsche. « Ça pense », mais nous pouvons comparer nos pensées et évaluer leurs conséquences.
Dans la mesure où les règles des programmes sont explicites, nous pouvons de même relier nos évaluations des résultats de ces programmes à ces règles, et tester des modifications de ces règles. Il restera toujours une part « aveugle » dans la computation, et cela peut devenir préoccupant, en particulier pour le « deep learning », pour lequel il devient vite trop complexe d’assigner certains résultats fâcheux à telle ou telle combinaison de règles. On est alors amené à laisser au programme le soin de modifier ses propres étapes en fonction de nos évaluations de ses conséquences, en attendant de pouvoir définir des classes de fonctions mathématiques et de modifications critiques de ces fonctions qui puissent « conceptualiser » les différences entre programmes en concurrence.
Un tel processus revient à penser avec le numérique, en sélectionnant au sein des simulations qu’il nous permet les potentialités inférentielles qui nous semblent attractives, et en nous réservant un droit critique et de révision. Et ces révisions pourront être plus averties, d’une part parce qu’elles seront secondées par des systèmes qui sont capables de déployer un nombre de pas d’inférence bien supérieur au nôtre, d’autre part parce que nous ne renoncerons pas pour autant à exercer cette capacité critique, enfin parce qu’elles feront partie du processus de mise à l’épreuve de nos concepts.
[1] Comprendre nos interactions sociales, une perspective de neuroéconomie, Schmidt et Livet, Odile Jacob, 2014.













Dans la partie « variations et innovations, » il me semble que vous oubliez un acteur, à savoir les média et l’émergence de concepts en lien avec l’actualité qui vont reconfigurer ses réseaux de concept. On voit aujourd’hui apparaître le mot « infodémie » qui met en relation l’idée de pandémie (actualité produite par les média en lien avec une situation bien sûr) et l’idée de mauvaise information. On pourrait faire la généalogie de ces concepts liées, de l’idée de manipulation, de propagande vers l’idée de désinformation, de mésinformation pour finir vers l’avant dernier avatar qui serait les fake news et pour finir l’infofémie (je ne dis pas que ces mots sont équivalents, je dis que la pression médiatique concoure aussi à forger de nouveau concept)
Précision par rapport à mon commentaire précédent, c’est bien l’irruption d’un évènement imprévu qui est à l’origine de la variation et non le media en lui même. Par contre le rôle du média est de choisir de mettre en avant l’évèneemnt